
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687 |
+91 8409492687 |  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comUpgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours on Instagram and YouTube and waste money on coffee and fast food, but won’t spend 30 minutes a day learning skills to boost our careers.
Master in DevOps, SRE, DevSecOps & MLOps!
Learn from Guru Rajesh Kumar and double your salary in just one year.

Amazon Data Firehose is a fully managed service for reliably loading streaming data into data lakes, data stores, and analytics tools. As organizations increasingly rely on real-time data for decision-making, understanding Firehose’s capabilities, components, and applications becomes essential for modern data architecture.
What is Amazon Data Firehose?
Amazon Data Firehose is a fully managed AWS service designed to capture, transform, and load streaming data into various destinations. It serves as an intermediary that efficiently manages data from multiple sources and enables applications to interact with this data in near real-time. As a serverless solution, it automatically scales to handle any amount of data without requiring manual intervention or ongoing administration.
Firehose can reliably load streaming data into data lakes, data stores, and analytics tools, making it an essential component in modern data processing pipelines. It supports various data destinations including Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Snowflake, Apache Iceberg tables, Amazon S3 Tables (preview), generic HTTP endpoints, and service providers like Datadog, New Relic, MongoDB, and Splunk.
The service is designed to handle continuous data streams from hundreds of thousands of sources simultaneously, processing gigabytes of data per second. This makes it ideal for applications requiring immediate insights rather than waiting for traditional batch processing.
Why is Amazon Data Firehose Used?
Organizations use Amazon Data Firehose for several compelling reasons:
- Simplified Data Ingestion: Firehose provides an easy way to capture and load streaming data without building complex data ingestion pipelines.
- Real-time Data Processing: It enables businesses to process and analyze data as it arrives, providing near real-time insights within seconds.
- Scalability: The service can handle massive amounts of data from hundreds of thousands of sources, automatically scaling to match throughput requirements.
- Data Transformation: Firehose can transform raw streaming data into formats required by destination data stores without building custom processing pipelines.
- Integration with AWS Ecosystem: It seamlessly integrates with over 20 AWS services, enabling comprehensive data processing workflows.
- Reduced Operational Overhead: As a fully managed service, Firehose eliminates the need for infrastructure management and ongoing administration.
- Cost Efficiency: The pay-as-you-go pricing model ensures organizations only pay for the resources they consume.
How Does Amazon Data Firehose Work?
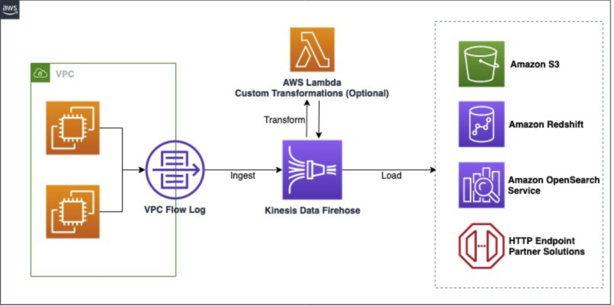
Amazon Data Firehose works by providing a pipeline for streaming data that enables near real-time processing. The basic workflow involves:
- Data Collection: Data producers send records to Firehose streams. These producers can include application logs, IoT devices, databases (preview), CloudWatch Logs, AWS WAF web ACL logs, AWS Network Firewall Logs, Amazon SNS, or AWS IoT.
- Data Buffering: Firehose buffers incoming data based on specified buffer size (in MB) and buffer interval (in seconds) before delivering it to destinations.
- Data Transformation (Optional): If enabled, Firehose can transform the data before delivery. Transformations include format conversion (to Parquet or ORC), decompression, custom transformations using AWS Lambda functions, or dynamic partitioning.
- Data Delivery: After processing, Firehose delivers the data to the specified destination. For S3 destinations, data is delivered directly to your bucket. For Redshift, data is first delivered to S3, then Firehose issues a COPY command to load it into Redshift. For other destinations like OpenSearch Service or Splunk, data is delivered directly while optionally backing up to S3.
- Error Handling: If delivery fails, Firehose implements retry mechanisms. For S3, it retries every 5 seconds for up to 24 hours. For Redshift, it retries every 5 minutes for up to 60 minutes before creating a manifest file for manual intervention.
The entire process is automated and managed by AWS, requiring minimal configuration and no ongoing administration.
Key Features of Amazon Data Firehose
Amazon Data Firehose offers several key features that make it a robust solution for streaming data processing:
Easy Launch and Configuration
You can create a Firehose delivery stream with just a few clicks in the AWS Management Console. Simply select your data source, configure optional transformations, and choose your destination. Once configured, Firehose continuously loads data into the specified destinations without requiring additional setup or management.
Elastic Scaling
Firehose automatically scales to handle varying data throughput. Once launched, your Firehose streams can handle gigabytes per second or more of input data rate while maintaining the specified data latency levels. This scaling happens automatically without any intervention or maintenance needed.
Near Real-time Data Delivery
Firehose loads new data into destinations within 60 seconds after the data is sent to the service. This near real-time capability allows you to access new data sooner and react to business and operational events faster. You can control delivery timing by specifying batch size or batch interval settings.
Support for Multiple Data Sources
Firehose can ingest data from over 20 different sources, including:
- Amazon MSK and MSK Serverless clusters
- Amazon Kinesis Data Streams
- Databases (preview)
- Amazon CloudWatch Logs
- AWS WAF web ACL logs
- AWS Network Firewall Logs
- Amazon SNS
- AWS IoT Core
- Direct PUT API
Data Format Conversion
Firehose supports converting data into columnar formats such as Apache Parquet and Apache ORC, which are optimized for cost-effective storage and analytics. This conversion happens before storing the data in Amazon S3, helping you save on storage and analytics costs when using services like Amazon Athena, Amazon Redshift Spectrum, or Amazon EMR.
Dynamic Partitioning
You can dynamically partition your streaming data before delivery to S3 using static or dynamically defined keys like “customer_id” or “transaction_id”. Firehose groups data by these keys and delivers into key-unique S3 prefixes, making it easier to perform high-performance, cost-efficient analytics.
Integrated Data Transformations
Firehose allows you to prepare your streaming data before it’s loaded to data stores. You can select an AWS Lambda function to automatically apply transformations to every input data record. AWS provides pre-built Lambda blueprints for converting common data sources such as Apache logs and system logs to JSON and CSV formats.
Multiple Destination Support
Firehose supports delivering data to various destinations including:
- Amazon S3
- Amazon Redshift
- Amazon OpenSearch Service
- Snowflake
- Apache Iceberg tables
- Amazon S3 Tables (preview)
- HTTP endpoints
- Service providers (Datadog, New Relic, MongoDB, Splunk)
Automatic Encryption
Firehose provides the option to automatically encrypt your data after it’s uploaded to the destination. You can specify an AWS Key Management System (KMS) encryption key as part of the Firehose stream configuration.
Comprehensive Monitoring
Firehose exposes several metrics through the console and Amazon CloudWatch, including volume of data submitted, volume of data uploaded to destination, time from source to destination, Firehose stream limits, throttled records number, and upload success rate.
Main Components of Amazon Data Firehose
Amazon Data Firehose comprises several main components that work together to enable efficient data streaming:
Firehose Streams
A Firehose stream is the underlying entity of the service. You use Firehose by creating a stream and then sending data to it. The stream handles all the scaling, sharding, and monitoring needed to continuously load data to destinations at the intervals you specify.
Records
Records represent the data of interest that your data producers send to a Firehose stream. A record can be as large as 1,000 KB. Firehose processes these records in near real-time according to your configuration.
Data Producers
Data producers are the sources that send records to Firehose streams. Examples include web servers sending log data, IoT devices transmitting telemetry, or applications generating event data. Firehose can also be configured to automatically read data from an existing Kinesis data stream.
Buffer Management
Firehose buffers incoming streaming data based on two parameters:
- Buffer Size: The amount of data (in MB) to buffer before delivery
- Buffer Interval: The time period (in seconds) to buffer data before delivery
These parameters help optimize delivery efficiency while maintaining near real-time processing.
Data Transformation Layer
If enabled, this component handles data transformations before delivery to destinations. Transformations can include format conversion, decompression, custom Lambda processing, or dynamic partitioning.
Delivery Management
This component manages the reliable delivery of data to destinations, handling retries and error reporting. It ensures data is delivered according to the specified configuration and manages the connection to various destination types.
When Should You Use Amazon Data Firehose?
Amazon Data Firehose is particularly well-suited for specific use cases:
- When you need near real-time data loading: If your applications require data to be available for analysis within seconds of generation, Firehose provides this capability without building custom solutions.
- When you want to eliminate operational overhead: For organizations looking to reduce the burden of managing data ingestion infrastructure, Firehose’s fully managed nature eliminates the need for provisioning, scaling, and monitoring servers.
- When dealing with variable data volumes: If your data generation patterns are unpredictable or vary significantly over time, Firehose’s automatic scaling capabilities ensure efficient handling without overprovisioning resources.
- When you need data format transformation: If your data needs to be converted to optimized formats like Parquet or ORC before analysis, Firehose handles this transformation automatically.
- When integrating with multiple AWS services: If your data architecture leverages various AWS services, Firehose’s native integration with over 20 AWS services simplifies your overall architecture.
- When building IoT analytics pipelines: For IoT applications generating continuous streams of sensor data, Firehose provides an ideal ingestion mechanism for real-time analytics.
- When implementing log analytics solutions: If you’re collecting and analyzing application logs, server logs, or network logs, Firehose streamlines the process of getting this data into analytical tools.
Benefits of Using Amazon Data Firehose
Amazon Data Firehose offers numerous benefits for organizations dealing with streaming data:
Easy to Use
Firehose provides a simple way to capture, transform, and load streaming data with minimal configuration. The service takes care of all the underlying complexity, including stream management, scaling, sharding, and monitoring, allowing you to focus on deriving insights from your data rather than managing infrastructure.
Serverless Architecture
As a fully managed service, Firehose eliminates the need to provision, configure, or scale servers. It automatically provisions, manages, and scales the compute, memory, and network resources required to handle your streaming data, regardless of volume or velocity.
Near Real-time Insights
Firehose delivers data to destinations within 60 seconds, enabling near real-time analytics and insights. This quick turnaround allows organizations to respond rapidly to changing conditions, identify issues promptly, and capitalize on emerging opportunities.
Cost Efficiency
With Firehose’s pay-as-you-go pricing model, you only pay for the volume of data you transmit through the service and any optional features like data format conversion or VPC delivery. There are no minimum fees, upfront commitments, or idle resource costs, making it a cost-effective solution for organizations of all sizes.
Seamless Integration
Firehose integrates natively with the broader AWS ecosystem, including data sources like Kinesis Data Streams, MSK, CloudWatch Logs, and IoT Core, as well as analytical services like Redshift, Athena, and EMR. This integration simplifies your overall architecture and enables comprehensive data processing pipelines.
Data Transformation Capabilities
Firehose’s built-in transformation capabilities allow you to prepare data before it reaches your destination, eliminating the need for separate transformation services or custom code. This includes format conversion, custom Lambda transformations, and dynamic partitioning.
Reliability and Durability
Firehose ensures reliable data delivery through automatic retries and error handling. For failed deliveries, it implements service-specific retry mechanisms and provides detailed error reporting to help troubleshoot issues.
Security
Firehose provides robust security features, including encryption of data in transit and at rest, integration with AWS Identity and Access Management (IAM) for access control, and VPC delivery options for enhanced network security.
Limitations or Challenges of Amazon Data Firehose
Despite its advantages, Amazon Data Firehose has several limitations to consider:
Throughput Limitations
By default, each Firehose stream can intake up to 2,000 transactions per second, 5,000 records per second, and 5 MB per second. While these limits can be increased through a service limit increase request, they represent initial constraints that might affect high-volume applications.
Data Delivery Semantics
Firehose uses at-least-once semantics for data delivery, which means that in rare circumstances, such as request timeouts upon delivery attempts, retry mechanisms could introduce duplicate records in your destination. Applications consuming this data need to be designed to handle potential duplicates.
Limited Transformation Capabilities
While Firehose offers basic transformation capabilities, complex data processing requirements might necessitate additional services or custom Lambda functions. The service primarily focuses on data movement rather than sophisticated processing.
Fixed Retry Policies
Firehose’s retry policies are fixed and cannot be customized. For S3 destinations, failed deliveries are retried every 5 seconds for up to 24 hours. For Redshift, retries occur every 5 minutes for up to 60 minutes before creating a manifest file for manual intervention. These policies might not align with all operational requirements.
Data Retention Limitations
Firehose doesn’t provide long-term storage for streaming data. Once data is delivered to the destination, it’s removed from the Firehose stream. If delivery fails beyond the maximum retry period, the data could be lost unless backup options are configured.
Limited Direct Query Capabilities
Unlike some streaming services that allow direct querying of in-flight data, Firehose requires data to be delivered to a destination before it can be queried or analyzed. This introduces some latency for analytical workloads.
Regional Availability
Firehose availability varies by AWS region, which might impact global deployments or disaster recovery strategies that span multiple regions.
How to Get Started with Amazon Data Firehose
Getting started with Amazon Data Firehose involves several steps:
Step 1: Set Up AWS Account and Permissions
Before using Firehose, you need an AWS account. If you don’t have one, you’ll need to sign up. Once you have an account, ensure you have the appropriate IAM permissions to create and manage Firehose resources.
Step 2: Access the Firehose Console
Navigate to the AWS Management Console and select Amazon Kinesis from the services menu. From there, select Data Firehose to access the Firehose console.
Step 3: Create a Delivery Stream
Click the “Create delivery stream” button to start the configuration process. You’ll need to provide a name for your delivery stream and configure the following components:
- Source: Select your data source, such as Direct PUT (API), Kinesis Data Stream, MSK, or other supported sources.
- Transform records (Optional): If needed, enable data transformation and select or create a Lambda function to process your data.
- Convert record format (Optional): If you want to convert data to Parquet or ORC format, enable this option and configure the schema.
- Destination: Choose your destination (S3, Redshift, OpenSearch Service, Splunk, HTTP endpoint, etc.) and provide the necessary configuration details.
- Backup settings (Optional): Configure backup options for your source data if desired.
- Advanced settings: Configure buffer size, buffer interval, compression, encryption, error logging, and other advanced options.
Step 4: Review and Create
Review your configuration settings and click “Create delivery stream” to create your Firehose stream.
Step 5: Send Data to Your Firehose Stream
Once your delivery stream is active, you can start sending data to it using one of the following methods:
- AWS SDK: Use the PutRecord or PutRecordBatch API operations in your application code.
- AWS CLI: Use the put-record or put-record-batch commands.
- Kinesis Agent: Install and configure the Kinesis Agent on your data sources to automatically send data to Firehose.
- Configured Source: If you selected a source like Kinesis Data Streams or MSK, data will flow automatically from that source.
Step 6: Monitor Your Firehose Stream
Use the Firehose console or CloudWatch metrics to monitor the performance and health of your delivery stream. Key metrics to watch include:
- IncomingBytes/IncomingRecords
- DeliveryToS3.Bytes/Records
- DeliveryToS3.Success
- BackupToS3.Bytes/Records
- ThrottledRecords
- DeliveryToS3.DataFreshness
Step 7: Optimize and Scale
Based on monitoring data, adjust your Firehose configuration to optimize performance and cost. This might include modifying buffer settings, requesting throughput limit increases, or refining transformation logic.
Alternatives to Amazon Data Firehose
While Amazon Data Firehose is a powerful solution for streaming data processing, several alternatives exist:
Apache Kafka
Apache Kafka is a distributed streaming platform known for its high throughput and fault tolerance. Unlike Firehose, Kafka requires self-management of infrastructure but offers more control over configuration and scaling. It’s ideal for organizations with existing Kafka expertise or those requiring features beyond what Firehose provides.
Google Cloud Pub/Sub
Google Cloud Pub/Sub is a messaging service that allows you to ingest, transform, and deliver event data. It offers real-time messaging, event ordering, and reliable message delivery. While it integrates well with Google Cloud Platform services, it has more limited data transformation capabilities compared to Firehose.
Azure Stream Analytics
Azure Stream Analytics is Microsoft’s real-time data streaming and analytics service. It features complex event processing, real-time analytics, and integration with Azure services. It offers SQL-like querying capabilities but may have limited scalability compared to Firehose.
Apache Flink
Apache Flink is a distributed stream processing framework known for its high performance and stateful processing capabilities. It offers exactly-once processing semantics, event time processing, and support for batch processing. While powerful, it has a steeper learning curve compared to Firehose and requires self-management.
Confluent Platform
Confluent Platform extends Apache Kafka with additional tools and services for managing and monitoring Kafka clusters. It includes a schema registry, Kafka Connect, and KSQL for stream processing. It provides an integrated platform for streaming data but comes with additional costs for enterprise features.
Elasticsearch Logstash
Elasticsearch Logstash is an open-source data processing pipeline that ingests data from multiple sources, transforms it, and sends it to various destinations. It offers plugins for different data inputs and outputs, data enrichment capabilities, and scalability. However, it requires more manual setup and configuration compared to Firehose.
StreamSets Data Collector
StreamSets Data Collector is an open-source data ingest platform for data movement between different sources and destinations. It handles data drift, monitors data quality, and supports various connectors. While flexible, it requires more technical expertise and configuration than Firehose.
Real-World Use Cases and Success Stories
Amazon Data Firehose has been successfully implemented across various industries:
Disney+
Disney+ uses Amazon Kinesis services, including Data Firehose, to drive real-time actions like providing title recommendations for customers, sending events across microservices, and delivering logs for operational analytics to improve the customer experience. They built real-time data-driven capabilities on a unified streaming platform that ingests billions of events per hour, processes and analyzes that data, and uses Firehose to deliver data to destinations without servers or code. These services helped Disney+ scale its viewing experience to tens of millions of customers with the required quality and reliability.
IoT Analytics
Manufacturing companies use Firehose to capture data continuously from connected devices such as industrial equipment, embedded sensors, and monitoring systems. Firehose loads the data into S3, Redshift, and OpenSearch Service, enabling near real-time access to metrics, insights, and dashboards. This allows for predictive maintenance, quality control, and operational efficiency improvements.
Clickstream Analytics
E-commerce platforms use Firehose to enable delivery of real-time metrics on digital content, enabling marketers to connect with their customers more effectively. They stream billions of small messages that are compressed, encrypted, and delivered to OpenSearch Service and Redshift. From there, they aggregate, filter, and process the data, and refresh content performance dashboards in near real-time.
Log Analytics
Organizations across industries use Firehose to collect, monitor, and analyze log data. By installing the Kinesis Agent on servers to automatically watch application and server log files and send the data to Firehose, they can detect application errors as they happen and identify root causes. Firehose continuously streams the log data to OpenSearch Service, enabling visualization and analysis with tools like Kibana.
Financial Services
Financial institutions leverage Firehose for real-time fraud detection, monitoring market data feeds, and analyzing trading patterns. By processing transaction data in near real-time, they can identify suspicious activities, respond to market changes, and optimize trading strategies
Citations: