Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours on Instagram and YouTube and waste money on coffee and fast food, but won’t spend 30 minutes a day learning skills to boost our careers.
Master in DevOps, SRE, DevSecOps & MLOps!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Source – sdtimes.com
If you google “matrix from hell,” you’ll see many articles about how Docker solves the matrix from hell. So, what is the matrix from hell? Put simply, it is the challenge of packaging any application, regardless of language/frameworks/dependencies, so that it can run on any cloud, regardless of operating systems/hardware/infrastructure.
 The original matrix from hell: applications were tightly coupled with underlying hardware
The original matrix from hell: applications were tightly coupled with underlying hardware
Docker solved for the matrix from hell by decoupling the application from the underlying operating system and hardware. It did this by packaging all dependencies inside Docker containers, including the OS. This makes Docker containers “portable,” i.e. they can run on any cloud or machine without the dreaded “it works on this machine” problems. This is the single biggest reason Docker is considered the hottest new technology of the last decade.
With DevOps principles gaining center stage over the last few years, Ops teams have started automating their tasks like provisioning infrastructure, managing config, triggering production deployments, etc. IT automation tools like Ansible and Terraform help tremendously with these use cases since they allow you to represent your infrastructure-as-code, which can be versioned and committed to source control. Most of these tools are configured with a YAML or JSON based language which describes the activity you’re trying to achieve.
The new matrix from hell
Let’s consider a simple scenario. You have a three-tier application with API, middleware, and web layers, and three environments: test, staging and production. You’re using a container service such as Kubernetes, though this example is true of all similar platforms like Amazon ECS, Docker Swarm and Google Container Engine (GKE). Here is how your config looks:
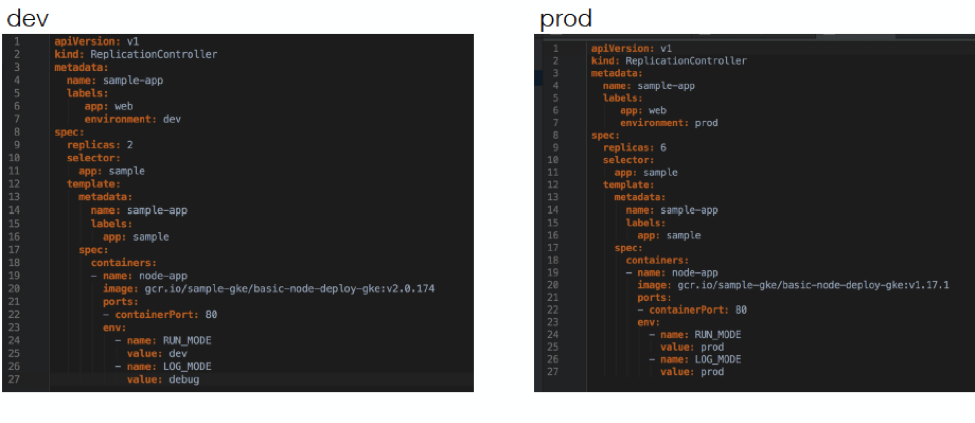
Notice the problem? The configuration of the app changes in each environment. You therefore need a config file that is specific to application/service/microservice and the environment!
Your first instinct is probably to point out that you can, in fact, templatize the YAML scripts. For example, the following config would ensure that the same YAML will work across all environments and apps:
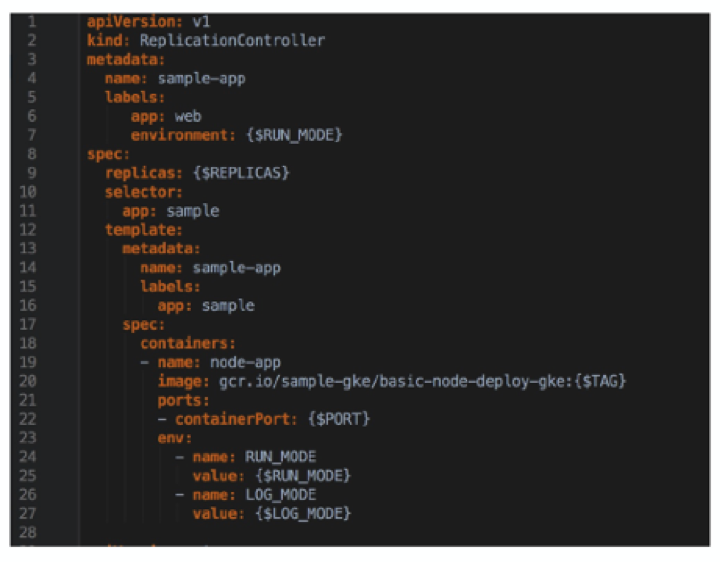
In theory, this is correct. A string replace will replace all values depending on the application-environment combination, and you should be good to go.
However, this approach also has a few issues:
- There are no audit trails, so you have no information about the application version that was deployed, who deployed it, or when. You don’t even know what the exact configuration was, unless you have knowledge of where the config is stored and can access it.
- There is no repeatability, so you cannot just go run an earlier config. Rollbacks or roll forwards are super challenging.You can potentially solve this by archiving all deployment files on S3 or GitHub, but now you have to secure secrets that should not be in cleartext, which creates its own nightmare.
- You also need a way to actually figure out what the values are for each deployment and to set the environment variables before the scripts are executed. For example, the value for $TAG in the snippet above will change for each deployment. You need to maintain this information somewhere and update it for each deployment, but now you need application-environment specific config files anyway.
- The biggest issue is that there is no way to do a string replace for tags that aren’t in the template. Not every environment needs every tag, so it is incredibly difficult to create a template config that can describe the application’s deployment into every environment.
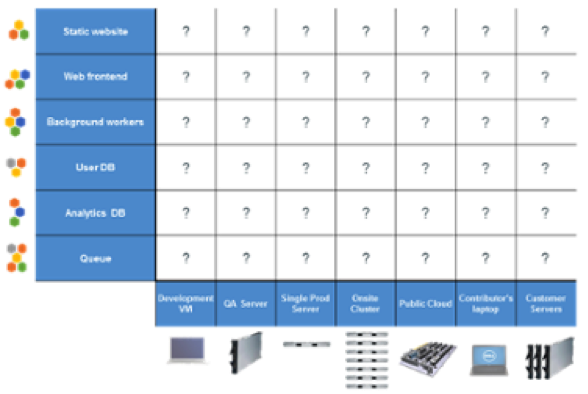
Faced with these challenges, most teams don’t bother templatizing and take the path of least resistance – creating deployment config files that are app-env specific. And this leads to… a DevOps matrix from hell! Can you imagine the matrix below for 50+ microservices?

The DevOps matrix from hell: automation scripts are tightly coupled with app/env combination
Avoiding the DevOps matrix from hell
The fundamental issue behind this new matrix from hell is that application configuration is currently being treated as a design-time decision with static deployment config files. You can only change this by having the ability to dynamically generate the Deployment config, depending on the requirements for an environment. This configuration consists of two parts:
- Environment specific settings, such as number of instances of the application
- Container specific settings that do not change across environments, such as the Tag you want to deploy, or CPU/memory requirements
To generate the deployment config dynamically at runtime, your automation platform needs to be aware of the environment the application is being deployed to, as well as knowledge of the package version that needs to be deployed.

The image above shows a conceptual workflow of how you can dynamically generate your Deployment config:
- my-app-code is the source code repository. Any commit to my-app-repo triggers the CI job, run-CI.
- run-CI builds and tests the source code, and then creates an application package my-app-pkg, which can be a JAR/WAR file, Docker image, etc. This is pushed to a Hub like Amazon ECR or JFrog Artifactory.
- The create-svc-defn job creates a Service definition for the application. This includes my-app-pkg and a bunch of config that is needed to run the application, represented as pkg-options. This could be settings for CPU, memory, ports, volumes, etc.
- The deploy-app-to-env-1 job takes this service definition and also some environment specific options env-1-options, such as number of instances you want to run in env-1. It generates the Deployment config for env-1 and deploys the application there.
- Later, when deploying the same service definition to env-2, the deploy-app-to-env-2 job takes env-2-options and if needed, the package options can also be overriden with pkg-options-override. It generates the Deployment config for env-2 and deploys the application there.
A DevOps assembly line platform can help avoid config sprawl and the DevOps matrix from hell by configuring the workflow above fairly easily, while also giving you repeatability and audit trails. You can also go the DIY route with Jenkins/Ansible combination and use S3 for storage of state, but that would require extensive scripting and handling state and versions yourself. Whatever path you choose to take, it is better to have a process and workflow in place as soon as possible, to avoid building technical debt as you adopt microservices or build smaller applications.