
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687 |
+91 8409492687 |  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comUpgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours on Instagram and YouTube and waste money on coffee and fast food, but won’t spend 30 minutes a day learning skills to boost our careers.
Master in DevOps, SRE, DevSecOps & MLOps!
Learn from Guru Rajesh Kumar and double your salary in just one year.
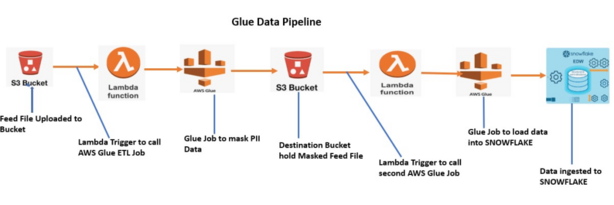
What is AWS Glue?
AWS Glue is a serverless data integration service provided by Amazon Web Services that makes it easy for analytics users to discover, prepare, move, and integrate data from multiple sources. Launched as part of AWS’s suite of data services, Glue serves as a comprehensive solution for organizations looking to streamline their data processing workflows without managing infrastructure.
As a fully managed ETL (Extract, Transform, Load) service, AWS Glue allows you to easily move data between different data sources and targets. It’s designed to handle various data processing needs, from simple data transfers to complex transformations, making it suitable for analytics, machine learning, and application development.
The serverless nature of AWS Glue means there’s no infrastructure to provision or manage. This eliminates the operational overhead typically associated with traditional ETL tools and allows organizations to focus on deriving value from their data rather than managing the underlying infrastructure.
AWS Glue supports a wide range of data sources and destinations, connecting to more than 70 diverse data sources, and enables users to manage their data in a centralized data catalog. This makes it an ideal solution for organizations looking to build data lakes, data warehouses, or implement comprehensive data integration strategies.
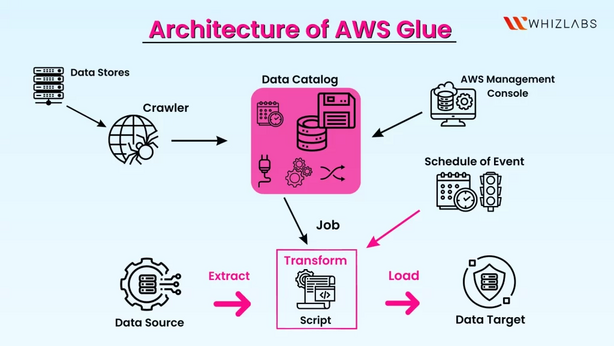
Why is AWS Glue Used?
Organizations leverage AWS Glue for several compelling reasons, all centered around simplifying data integration and maximizing the value of their data assets:
Simplified Data Integration
AWS Glue consolidates major data integration capabilities into a single service, including data discovery, modern ETL, cleansing, transforming, and centralized cataloging. This comprehensive approach eliminates the need for multiple specialized tools and provides a unified platform for all data integration needs.
Serverless Architecture
The serverless nature of AWS Glue removes the burden of infrastructure management. Organizations don’t need to worry about provisioning, scaling, or maintaining servers, which significantly reduces operational overhead and allows teams to focus on data processing logic rather than infrastructure concerns.
Support for Various Data Processing Paradigms
AWS Glue provides flexible support for various data processing approaches, including traditional ETL (Extract, Transform, Load), ELT (Extract, Load, Transform), and streaming data processing. This versatility makes it suitable for a wide range of use cases and data processing requirements.
Seamless AWS Integration
AWS Glue integrates seamlessly with other AWS services, particularly the analytics ecosystem. It works well with services like Amazon S3, Amazon Redshift, Amazon Athena, Amazon EMR, and many others, enabling comprehensive data processing pipelines within the AWS ecosystem.
Cost Efficiency
With AWS Glue’s pay-as-you-go pricing model, organizations only pay for the resources they use during job execution. This eliminates the need for upfront investments in infrastructure and ensures cost-effective data processing, especially for workloads with variable resource requirements.
Automated Schema Discovery
AWS Glue can automatically discover and infer schemas from various data sources through its crawler functionality. This automation reduces the manual effort required to catalog data and ensures that the metadata in the Data Catalog remains up-to-date.
How Does AWS Glue Work?
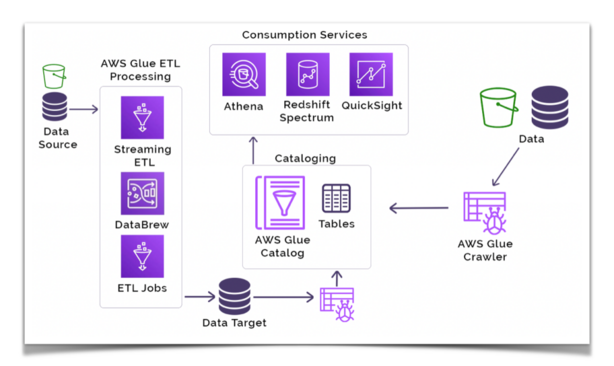
AWS Glue operates through a well-defined workflow that orchestrates the ETL process from data discovery to transformation and loading. Here’s a detailed look at how AWS Glue works:
Data Discovery and Cataloging
The process begins with data discovery, where AWS Glue crawlers connect to data sources, infer schemas, and populate the AWS Glue Data Catalog with metadata. Crawlers can be scheduled to run periodically, ensuring that the Data Catalog remains up-to-date as data evolves.
Job Definition and Development
Once data is cataloged, users define ETL jobs that specify the source data, transformation logic, and target destinations. AWS Glue provides multiple options for job development:
- Visual ETL: Using AWS Glue Studio, users can visually compose data transformation workflows through a graphical interface.
- Script-based ETL: For more complex transformations, users can write custom scripts in Python or Scala, leveraging AWS Glue’s built-in transformation libraries.
Job Execution
When a job is triggered (either on schedule, on demand, or based on an event), AWS Glue provisions the necessary resources in its service account to execute the job. It creates an isolated environment for each job, ensuring security and performance isolation.
AWS Glue runs ETL jobs in a serverless environment using either Apache Spark or Ray as the execution engine. The service automatically handles resource provisioning, scaling, and management, ensuring optimal performance without manual intervention.
Data Transformation and Loading
During job execution, AWS Glue extracts data from the specified sources, applies the defined transformations, and loads the processed data into the target destinations. The transformation logic can include various operations such as filtering, joining, aggregating, and format conversion.
Monitoring and Logging
Throughout the execution, AWS Glue captures logs and metrics that provide visibility into job performance and execution status. These logs are accessible through the AWS Glue console or programmatically through AWS CloudWatch, enabling effective monitoring and troubleshooting.
Resource Cleanup
Once a job completes, AWS Glue automatically releases the provisioned resources, ensuring cost efficiency. The service follows a pay-as-you-go model, charging only for the resources used during job execution.
Key Features of AWS Glue
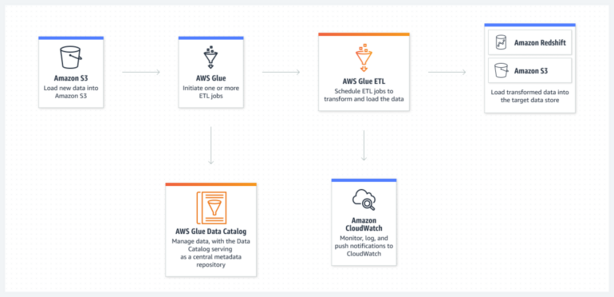
AWS Glue offers a rich set of features designed to simplify data integration and maximize productivity. Here are the key features that make AWS Glue a powerful solution for data integration:
Automated Schema Discovery and Cataloging
AWS Glue crawlers automatically scan data sources, infer schemas, and populate the Data Catalog with metadata. This automation reduces the manual effort required to catalog data and ensures that the metadata remains accurate and up-to-date.
Visual ETL Development
AWS Glue Studio provides a graphical interface for designing ETL workflows. Users can visually compose data transformation pipelines by dragging and dropping components, specifying transformations, and configuring job properties, all without writing code.
Script-based ETL Development
For more complex transformations, AWS Glue supports script-based ETL development using Python or Scala. The service provides built-in transformation libraries and utilities that simplify common ETL operations while offering the flexibility of custom code.
Serverless Execution
AWS Glue automatically provisions and manages the resources required to run ETL jobs. This serverless approach eliminates the need for infrastructure management and ensures that resources scale according to workload demands.
Job Scheduling and Triggering
AWS Glue provides flexible options for job scheduling and triggering. Jobs can be scheduled to run at specific intervals, triggered by events (such as the arrival of new data), or executed on demand through the console or API.
Data Format Conversion
AWS Glue supports conversion between various data formats, including CSV, JSON, Parquet, ORC, and Avro. This capability simplifies data preparation for analytics and ensures compatibility with different data processing systems.
Data Quality and Validation
AWS Glue provides built-in data quality features that allow users to define and enforce data quality rules. These rules can validate data against predefined criteria, identify anomalies, and ensure that data meets quality standards before it’s used for analytics or decision-making.
Streaming ETL
In addition to batch processing, AWS Glue supports streaming ETL, enabling real-time data processing and analytics. This capability allows organizations to derive insights from data as it’s generated, rather than waiting for batch processing windows.
Bookmarking and Job Resumption
AWS Glue uses job bookmarks to track data that has been processed by previous job runs. This feature prevents the reprocessing of old data, saving time and resources by focusing only on new or changed data.
Comprehensive Monitoring and Logging
AWS Glue integrates with AWS CloudWatch to provide detailed monitoring and logging capabilities. Users can track job execution, monitor resource utilization, and troubleshoot issues through comprehensive logs and metrics.
Main Components of AWS Glue
AWS Glue consists of several core components that work together to enable seamless data integration. Understanding these components is essential for effectively leveraging AWS Glue:
AWS Glue Data Catalog
The Data Catalog is a central metadata repository that stores information about data sources, transformations, and targets. It serves as a unified catalog for all data assets, enabling discovery, governance, and management. The catalog contains:
- Databases: Logical containers for organizing tables
- Tables: Metadata definitions that map to data stored in various locations
- Connections: Information required to connect to data sources and targets
- Crawlers: Configurations for automatically discovering and cataloging data
AWS Glue Crawlers
Crawlers are programs that connect to data sources, infer schemas, and create or update metadata table definitions in the Data Catalog. They can be scheduled to run periodically, ensuring that the catalog remains up-to-date as data evolves. Crawlers support various data sources, including:
- Amazon S3
- Amazon RDS and Amazon Redshift
- Amazon DynamoDB
- JDBC-compatible databases
- MongoDB and DocumentDB
AWS Glue ETL Jobs
ETL jobs contain the business logic for extracting data from sources, transforming it using Apache Spark or Ray scripts, and loading it into targets. Jobs can be developed using:
- AWS Glue Studio: A visual interface for designing ETL workflows
- Script Editor: For writing custom Python or Scala scripts
- Notebook Interface: For interactive development using Jupyter notebooks
AWS Glue Triggers
Triggers are mechanisms that initiate job runs based on various conditions:
- Schedule-based Triggers: Run jobs at specified intervals
- Event-based Triggers: Run jobs in response to events, such as the completion of another job or the arrival of new data
- On-demand Triggers: Run jobs manually through the console or API
AWS Glue Development Endpoints
Development endpoints provide environments for interactively developing and testing AWS Glue scripts. They enable developers to use tools like Jupyter notebooks for iterative development and debugging before deploying scripts to production.
AWS Glue Workflows
Workflows allow users to create and visualize complex ETL activities involving multiple crawlers, jobs, and triggers. They provide a way to model dependencies between different components and monitor the execution of the entire data processing pipeline.
When Should You Use AWS Glue?
AWS Glue is particularly well-suited for specific scenarios and use cases. Understanding when to use AWS Glue can help organizations make informed decisions about their data integration strategy:
Building Data Warehouses and Data Lakes
AWS Glue is ideal for organizations building enterprise-class data warehouses or data lakes. It facilitates the movement of data from various sources into centralized repositories, handling the validation, cleansing, organization, and formatting required for effective analytics.
Consolidating Data from Multiple Sources
When organizations need to consolidate data from various parts of their business into a central repository, AWS Glue provides the necessary capabilities to extract data from different sources, transform it into a consistent format, and load it into a unified data store.
Enabling Self-service Analytics
AWS Glue’s Data Catalog and integration with analytics services like Amazon Athena and Amazon Redshift Spectrum enable self-service analytics. Business users can discover and query cataloged data without understanding the underlying storage or format details.
Implementing Data Pipelines for Machine Learning
For organizations leveraging machine learning, AWS Glue can prepare and transform data into formats suitable for training and inference. Its integration with services like Amazon SageMaker streamlines the data preparation process for machine learning workflows.
Migrating from On-premises to Cloud
AWS Glue is valuable for organizations migrating data workloads from on-premises systems to the cloud. It can extract data from on-premises sources, transform it as needed, and load it into cloud-based storage or analytics services.
Processing Streaming Data
With its support for streaming ETL, AWS Glue is suitable for processing real-time data streams from sources like Amazon Kinesis or Apache Kafka. This capability enables organizations to derive insights from data as it’s generated, supporting real-time analytics and decision-making.
Implementing Data Governance and Compliance
AWS Glue’s Data Catalog and integration with AWS Lake Formation provide the foundation for implementing data governance and compliance controls. Organizations can define and enforce access policies, track data lineage, and ensure compliance with regulatory requirements.
Benefits of Using AWS Glue
AWS Glue offers numerous benefits that make it an attractive choice for data integration:
Serverless Architecture
The serverless nature of AWS Glue eliminates the need for infrastructure provisioning and management. Organizations don’t need to worry about capacity planning, scaling, or maintenance, reducing operational overhead and allowing teams to focus on data processing logic.
Cost Efficiency
With AWS Glue’s pay-as-you-go pricing model, organizations only pay for the resources used during job execution. This eliminates upfront investments in infrastructure and ensures cost-effective data processing, especially for workloads with variable resource requirements.
Reduced Development Time
AWS Glue’s visual interface, built-in transformations, and automated schema discovery significantly reduce development time. Organizations can quickly build and deploy ETL workflows without extensive coding or manual schema definition.
Scalability
AWS Glue automatically scales resources based on workload demands, ensuring optimal performance regardless of data volume or complexity. This scalability allows organizations to process data of any size without manual intervention.
Integration with AWS Ecosystem
AWS Glue integrates seamlessly with other AWS services, particularly the analytics ecosystem. This integration enables comprehensive data processing pipelines and simplifies the overall architecture for data analytics and machine learning.
Automated Maintenance
AWS Glue handles routine maintenance tasks such as patching, upgrades, and scaling, reducing the operational burden on IT teams. This automation ensures that the service remains up-to-date and secure without manual intervention.
Comprehensive Monitoring
AWS Glue provides detailed monitoring and logging capabilities through integration with AWS CloudWatch. Organizations can track job execution, monitor resource utilization, and troubleshoot issues through comprehensive logs and metrics.
Data Governance and Security
AWS Glue integrates with AWS Lake Formation and AWS Identity and Access Management (IAM) to provide robust data governance and security controls. Organizations can define and enforce access policies, encrypt sensitive data, and ensure compliance with regulatory requirements.
Limitations or Challenges of AWS Glue
Despite its many advantages, AWS Glue has certain limitations and challenges that organizations should consider:
Learning Curve
While AWS Glue provides a visual interface for ETL development, leveraging its full capabilities may require familiarity with Apache Spark, Python, or Scala. This learning curve can be steep for teams without prior experience in these technologies.
Startup Latency
AWS Glue jobs experience some startup latency due to the provisioning of resources in the serverless environment. This latency can impact use cases requiring immediate processing, although AWS Glue maintains a warm pool of instances to reduce startup time.
Limited Control Over Infrastructure
The serverless nature of AWS Glue means that organizations have limited control over the underlying infrastructure. While this reduces operational overhead, it may not be suitable for scenarios requiring specific infrastructure configurations or optimizations.
Cost Management
While AWS Glue’s pay-as-you-go pricing can be cost-effective, inefficient jobs or frequent executions can lead to higher costs. Organizations need to implement proper cost monitoring and optimization strategies to manage expenses effectively.
Complex Debugging
Debugging AWS Glue jobs can be challenging, especially for complex transformations or performance issues. The distributed nature of Spark jobs adds complexity to the debugging process, requiring specialized knowledge and tools.
Limited Support for Real-time Processing
Although AWS Glue supports streaming ETL, its capabilities for real-time processing are not as mature as dedicated stream processing frameworks like Apache Flink or Apache Kafka Streams. Organizations with advanced real-time processing requirements may need to consider additional solutions.
Regional Availability
AWS Glue availability varies by AWS region, which might impact global deployments or disaster recovery strategies that span multiple regions.
How to Get Started with AWS Glue
Getting started with AWS Glue involves several steps, from setting up the necessary permissions to creating and running ETL jobs:
Step 1: Set Up AWS Account and Permissions
Before using AWS Glue, ensure you have an AWS account and the appropriate IAM permissions. Create an IAM role with the necessary permissions for AWS Glue to access your data sources and targets.
Step 2: Access the AWS Glue Console
Navigate to the AWS Management Console and select AWS Glue from the services menu. This will take you to the AWS Glue console, where you can manage all aspects of the service.
Step 3: Define Connections (if needed)
If your data sources or targets require specific connection information (such as JDBC databases), create connections in the AWS Glue console. Connections store the necessary parameters for AWS Glue to access these resources.
Step 4: Crawl Your Data Sources
Create and run crawlers to discover and catalog your data sources. Configure the crawler with the appropriate data source information, target database in the Data Catalog, and schedule if needed.
Step 5: Explore the Data Catalog
Once the crawler completes, explore the Data Catalog to view the discovered tables and their schemas. This metadata will be used to define your ETL jobs.
Step 6: Create an ETL Job
Create an ETL job using either AWS Glue Studio (visual interface) or the script editor (for custom Python or Scala scripts). Define the source data, transformation logic, and target destinations based on your requirements.
Step 7: Configure Job Properties
Configure job properties such as the IAM role, number of workers, worker type, and job bookmarks. These settings determine how the job executes and manages resources.
Step 8: Run and Monitor the Job
Run the job either manually or by setting up triggers for scheduled or event-based execution. Monitor the job’s progress and performance through the AWS Glue console or CloudWatch logs.
Step 9: Iterate and Optimize
Based on the job’s performance and results, iterate on your ETL logic and optimize job configurations for better efficiency and cost-effectiveness.
Step 10: Implement Production Workflows
Once your individual jobs are working correctly, implement production workflows that orchestrate multiple jobs, crawlers, and triggers to create end-to-end data processing pipelines.
Alternatives to AWS Glue
While AWS Glue is a powerful data integration service, several alternatives exist that may be more suitable for specific use cases:
Apache Airflow
Apache Airflow is an open-source platform for programmatically authoring, scheduling, and monitoring workflows. It provides a rich ecosystem of operators and hooks for various data sources and targets, making it suitable for complex orchestration scenarios.
Apache NiFi
Apache NiFi is a dataflow management system designed to automate the flow of data between systems. It provides a web-based user interface for designing, controlling, and monitoring data flows, with support for real-time processing and data provenance.
Talend
Talend is a comprehensive data integration platform that offers a wide range of connectors, transformations, and management capabilities. It provides both open-source and commercial editions, with features for data quality, master data management, and application integration.
Informatica PowerCenter
Informatica PowerCenter is an enterprise-grade data integration platform known for its robust capabilities in handling complex transformations and large-scale data processing. It offers advanced features for data quality, metadata management, and data governance.
Microsoft Azure Data Factory
Azure Data Factory is Microsoft’s cloud-based data integration service, similar to AWS Glue. It provides capabilities for data movement, transformation, and orchestration, with integration to Azure’s analytics and storage services.
Google Cloud Dataflow
Google Cloud Dataflow is a fully managed service for transforming and enriching data in stream and batch modes. It’s based on Apache Beam, providing a unified programming model for both batch and streaming data processing.
Stitch
Stitch is a cloud-based ETL service focused on simplicity and ease of use. It’s particularly well-suited for loading data from various sources into data warehouses like Snowflake, Amazon Redshift, or Google BigQuery.
dbt (data build tool)
dbt is a transformation tool that enables data analysts and engineers to transform data in their warehouses using SQL. It’s not a complete ETL solution but excels at the transformation phase, particularly for organizations following the ELT (Extract, Load, Transform) approach.
Real-World Use Cases and Success Stories
AWS Glue has been successfully implemented across various industries, solving real-world data integration challenges:
FinAccel: Streamlining ETL Processes
FinAccel, a technology company specializing in financial services, adopted AWS Glue to power their day-to-day ETL processes. After experimenting with different ETL frameworks, they found that AWS Glue provided the simplicity and efficiency they needed. The service enabled them to define and run ETL jobs without complicated server provisioning, particularly for loading data from their data lake to their Redshift warehouse.
The transformed data feeds into their BI tools for tracking key metrics and serves as the foundation for their credit scoring models, which have credit-scored millions of customers. As a hyper-growth startup, FinAccel particularly valued the cost-effectiveness of AWS Glue’s pay-as-you-go model, which allowed their small team of data engineers to run the entire data infrastructure efficiently.
ShopFully: Improving Marketing Campaign Efficiency
ShopFully, an Italian technology company, leveraged AWS Glue to maximize processing speeds for large amounts of data ingested from local shoppers’ app usage across hundreds of regions. Previously using a legacy data warehousing infrastructure and relational database, ShopFully needed a solution that could scale efficiently and affordably to process more than 100 million events in under 20 minutes.
By implementing AWS Glue, ShopFully significantly improved its ability to adjust marketing campaigns in near real-time. The company runs hundreds of thousands of marketing campaigns annually and now processes each campaign separately to track performance. AWS Gl