
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687 |
+91 8409492687 |  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comUpgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours on Instagram and YouTube and waste money on coffee and fast food, but won’t spend 30 minutes a day learning skills to boost our careers.
Master in DevOps, SRE, DevSecOps & MLOps!
Learn from Guru Rajesh Kumar and double your salary in just one year.

What is AWS Redshift?
AWS Redshift is a fully managed, cloud-based data warehousing solution provided by Amazon Web Services. It’s designed to handle and analyze massive volumes of structured and semi-structured data, capable of processing data in the range of exabytes (10^18 bytes). Redshift enables organizations to gain valuable insights from their data through fast querying and analysis.
As a petascale data warehouse service, Redshift is specifically built for business intelligence, analytics, and reporting applications. It allows users to store data from various sources in one centralized location, making it accessible for complex queries and analysis. With its serverless option, users can access and analyze data without manually configuring a provisioned data warehouse.
Redshift organizes data in a columnar format, which differs from traditional row-based databases. Each column contains data of a specific type (integers, text, dates), which enables more efficient storage and faster query execution. This columnar storage approach, combined with advanced compression techniques, allows Redshift to handle large-scale data workloads with exceptional performance.
The service is fully managed by AWS, eliminating the need for manual setup, configuration, and maintenance. Users can deploy a Redshift cluster with just a few clicks and start analyzing their data immediately using familiar SQL-based tools and business intelligence applications.
Why is AWS Redshift Used?
Organizations leverage AWS Redshift for several compelling reasons, all centered around efficient data analysis and deriving actionable insights:
Handling Large-Scale Data Analytics
Redshift excels at processing and analyzing large volumes of data efficiently. Its architecture is specifically designed to handle complex queries on massive datasets, making it ideal for organizations dealing with petabytes of data.
Business Intelligence and Reporting
Redshift allows organizations to build robust business intelligence and reporting solutions. It supports complex analytics on large volumes of data, enabling better business decision-making through comprehensive data analysis.
Data Warehousing
As a central repository for structured and semi-structured data, Redshift makes it easy to store, manage, and analyze vast amounts of data for historical reporting and analysis. It serves as a single source of truth for organizational data.
Machine Learning and Advanced Analytics
Redshift can be used as a data source for training machine learning models and performing advanced analytics. With Redshift ML, users can train ML models based on data available in the cluster and execute internal ML inference tasks through SQL statements.
ETL (Extract, Transform, Load) Pipelines
Organizations use Redshift in ETL pipelines to extract data from various sources, transform it according to business rules, and load it into Redshift for analysis. This streamlined approach to data processing enables more efficient data workflows.
IoT Analytics
For IoT (Internet of Things) applications, Redshift provides the capability to store, process, and analyze large volumes of sensor data and device telemetry. It supports both real-time and batch analytics on IoT data, enabling organizations to derive valuable insights from connected devices.
Log Analysis
Redshift is widely used for log analysis, allowing organizations to process and analyze large volumes of log data generated by applications, servers, or network devices. This capability helps in identifying patterns, troubleshooting issues, and improving system performance.
How Does AWS Redshift Work?
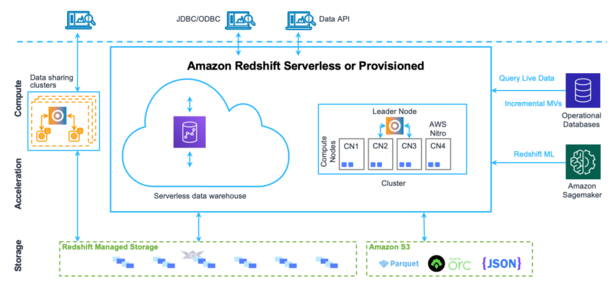
AWS Redshift works through a sophisticated architecture designed for high-performance data processing. Here’s a detailed look at how Redshift operates:
Columnar Data Storage
Redshift organizes data in a columnar format rather than the traditional row-based approach. This means that all values for a specific column are stored together, which enables more efficient compression and reduces I/O operations during query execution. Columnar storage is particularly effective for analytical queries that typically scan specific columns rather than entire rows.
Data Ingestion
Redshift pulls data from various sources such as Amazon S3, using formats like Parquet, ORC, or JSON. The data is stored in Redshift Managed Storage, which provides efficient storage capabilities. The integration with S3 enables Redshift to handle vast amounts of data with optimized storage.
Cluster Architecture
In provisioned mode, a Redshift cluster consists of a leader node and one or more compute nodes. The leader node coordinates query processing and communicates with client applications, while compute nodes handle parallel execution of queries. This distributed architecture enables Redshift to process complex queries efficiently.
Massively Parallel Processing (MPP)
Redshift uses MPP technology to distribute and process data across multiple nodes. When a query is submitted, the leader node creates an execution plan and distributes the workload across compute nodes, which process data in parallel. This approach significantly improves query performance, especially for large datasets.
Query Execution
When a query is submitted to Redshift, the leader node parses the query, develops an execution plan, and distributes the compiled code to the compute nodes. Each compute node executes the query on its portion of the data, and the results are aggregated by the leader node before being returned to the client.
Dynamic Resource Allocation
Redshift dynamically allocates processing and memory resources to handle higher demand. This capability allows thousands of queries to be sent to the dataset simultaneously without performance degradation. In serverless mode, Redshift automatically scales compute resources based on workload demands.
Data Compression
To optimize storage and improve query performance, Redshift employs advanced compression techniques. The service analyzes the data and selects the most appropriate compression algorithm for each column, which reduces storage requirements and improves I/O performance.
Machine Learning Integration
Redshift uses machine learning to predict and analyze queries, which further enhances performance. This predictive capability, combined with MPP technology, makes Redshift faster than many other data warehousing solutions in the market.
Key Features of AWS Redshift
AWS Redshift offers a rich set of features that make it a powerful solution for data warehousing and analytics:
Scalability
Redshift can scale from a few hundred gigabytes to a petabyte or more, accommodating growing data needs without manual intervention. This scalability ensures that organizations can handle increasing data volumes without performance degradation.
Columnar Storage and Compression
Redshift utilizes columnar storage and data compression to optimize query performance. This approach reduces I/O operations and allows more data to be loaded into memory, resulting in faster query execution.
Fully Managed Service
As a fully managed service, Redshift eliminates the need for manual setup, configuration, and maintenance. AWS handles the underlying infrastructure, allowing users to focus on data analysis rather than infrastructure management.
Security
Redshift provides robust security features, including encryption at rest and in transit, VPC integration, and IAM roles. These security measures ensure that sensitive data remains protected throughout the data processing lifecycle.
Familiar SQL Interface
Redshift offers a familiar SQL interface and compatibility with popular business intelligence tools. This compatibility allows users to leverage existing SQL skills and tools, reducing the learning curve for adoption.
Performance
Redshift enables fast data analysis through optimized query performance. Its columnar storage, compression techniques, and MPP architecture work together to deliver exceptional performance, even for complex queries on large datasets.
Cost-Effectiveness
With Redshift, users only pay for the storage and compute resources they consume. This pay-as-you-go model ensures cost-effectiveness, especially for organizations with variable workload demands.
Integration with AWS Services
Redshift integrates seamlessly with other AWS services, including S3, Lambda, and SageMaker. This integration facilitates end-to-end data solutions and enables comprehensive data processing pipelines within the AWS ecosystem.
Redshift Serverless
Redshift Serverless automatically provisions and scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads. Users pay only for the resources they use, with no charges when the data warehouse is idle.
Machine Learning Capabilities
Redshift ML allows users to create, train, and deploy machine learning models using familiar SQL commands. This feature simplifies the process of incorporating machine learning into data analysis workflows.
Main Components of AWS Redshift
AWS Redshift consists of several key components that work together to provide a comprehensive data warehousing solution:
Leader Node
The leader node in a Redshift cluster manages all external and internal communication. It’s responsible for preparing query execution plans whenever a query is submitted to the cluster. Once the execution plan is ready, the leader node distributes the query execution code to the compute nodes and assigns slices of data to each compute node for computation of results.
The leader node handles queries that don’t involve accessing data stored on compute nodes, while distributing more complex queries to the compute nodes. It serves as the single SQL endpoint for the cluster and aggregates results from all compute nodes before returning them to the client.
Compute Nodes
Compute nodes are responsible for the actual execution of queries and have data stored with them. They execute queries assigned by the leader node and return intermediate results, which are then aggregated by the leader node.
There are two types of compute nodes available in Redshift:
- Dense Storage (DS): These nodes allow the creation of large data warehouses using Hard Disk Drives (HDDs) for a low price point.
- Dense Compute (DC): These nodes enable high-performance data warehouses using Solid-State Drives (SSDs) for faster query execution.
Each compute node has its own CPU, memory, and disk storage, which are used to process the portion of a query assigned to it.
Node Slices
A compute node consists of slices, with each slice having a portion of the compute node’s memory and disk assigned to it. Slices perform query operations in parallel, working on different portions of the data simultaneously. The leader node assigns query code and data to slices for execution.
Data is distributed among the slices based on the distribution style and distribution key of a particular table. An even distribution of data enables Redshift to assign workload evenly to slices, maximizing the benefit of parallel processing.
Massively Parallel Processing (MPP)
MPP is a fundamental component of Redshift’s architecture, allowing for fast processing of complex queries on large datasets. Multiple compute nodes execute the same query code on portions of data in parallel, significantly improving performance compared to traditional sequential processing.
Columnar Data Storage
Redshift stores data in a columnar fashion, which drastically reduces disk I/O and minimizes the amount of data loaded into memory during query execution. This approach speeds up query execution and enables more efficient in-memory processing.
Data Compression
Data compression is a critical component that ensures query performance by reducing the storage footprint and enabling faster data loading into memory. Redshift uses adaptive compression encoding depending on the column data type, optimizing storage and performance.
Query Optimizer
Redshift’s query optimizer generates efficient query plans that leverage MPP and columnar data storage. It analyzes table information to create optimal execution strategies, ensuring fast query performance even for complex analytical queries.
Cluster Internal Network
Redshift provides private and high-speed network communication between the leader node and compute nodes. This internal network uses high-bandwidth connections and custom communication protocols to ensure efficient data transfer within the cluster. The compute nodes operate on an isolated network that cannot be accessed directly by client applications, enhancing security.
When Should You Use AWS Redshift?
AWS Redshift is particularly well-suited for specific scenarios and use cases. Understanding when to use Redshift can help organizations make informed decisions about their data warehousing strategy:
For Business Intelligence and Reporting
Redshift is ideal when you need to build robust business intelligence and reporting solutions that support business decisions based on large volumes of data and complex analytics. Its ability to handle complex queries on massive datasets makes it perfect for generating comprehensive reports and dashboards.
For Data Warehousing
When you need a central repository for structured and semi-structured data, Redshift serves as an excellent solution. It makes it easy to store, manage, and analyze vast amounts of data for historical reporting and analysis, providing a single source of truth for organizational data.
For Machine Learning and Advanced Analytics
If your organization needs to train machine learning models or perform advanced analytics on large datasets, Redshift provides the necessary infrastructure and capabilities. With Redshift ML, you can create, train, and deploy machine learning models using familiar SQL commands.
For ETL Pipelines
Redshift is well-suited for ETL pipelines, allowing you to extract data from various sources, transform it according to business rules, and load it into a centralized repository for analysis. This streamlined approach to data processing enables more efficient data workflows.
For IoT Analytics
When dealing with large volumes of sensor data and device telemetry from IoT devices, Redshift provides the capability to store, process, and analyze this data efficiently. It supports both real-time and batch analytics on IoT data, enabling valuable insights from connected devices.
For Log Analysis
If your organization needs to process and analyze large volumes of log data generated by applications, servers, or network devices, Redshift offers the necessary scalability and performance. This capability helps in identifying patterns, troubleshooting issues, and improving system performance.
When Dealing with Large-Scale Data
Redshift is particularly valuable when your organization needs to analyze petabytes of data efficiently. Its architecture is specifically designed to handle massive datasets with optimal performance, making it ideal for organizations with large-scale data requirements.
Benefits of Using AWS Redshift
AWS Redshift offers numerous benefits that make it an attractive choice for data warehousing and analytics:
High Performance
Redshift provides exceptional query performance through its columnar storage, efficient compression techniques, and massively parallel processing technology. It can handle large-scale data workloads and deliver swift responses to complex queries, allowing organizations to make decisions faster.
Scalability
Redshift can scale from a few hundred gigabytes to a petabyte or more, accommodating growing data needs without manual intervention. This scalability ensures that organizations can handle increasing data volumes without performance degradation, making it a future-proof solution.
Cost-Effectiveness
With Redshift’s pay-as-you-go pricing model, organizations only pay for the storage and compute resources they consume. This approach eliminates the need for upfront investments in infrastructure and ensures cost-effective data processing, especially for workloads with variable resource requirements.
Ease of Use
Redshift enables users to quickly start querying and visualizing data through its familiar SQL interface and compatibility with popular business intelligence tools. This ease of use reduces the learning curve for adoption and allows organizations to derive value from their data more rapidly.
Integration with AWS Ecosystem
Redshift integrates seamlessly with other AWS services, including S3, Lambda, and SageMaker. This integration facilitates end-to-end data solutions and enables comprehensive data processing pipelines within the AWS ecosystem, enhancing overall efficiency.
Security
Redshift provides robust security features, including encryption at rest and in transit, VPC integration, and IAM roles. These security measures ensure that sensitive data remains protected throughout the data processing lifecycle, meeting regulatory requirements and organizational security standards.
Fully Managed Service
As a fully managed service, Redshift eliminates the need for manual setup, configuration, and maintenance. AWS handles the underlying infrastructure, allowing users to focus on data analysis rather than infrastructure management, reducing operational overhead.
Serverless Option
Redshift Serverless automatically provisions and scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads. Users pay only for the resources they use, with no charges when the data warehouse is idle, providing additional flexibility and cost efficiency.
Machine Learning Capabilities
Redshift ML allows users to create, train, and deploy machine learning models using familiar SQL commands. This feature simplifies the process of incorporating machine learning into data analysis workflows, enabling more sophisticated insights from data.
Limitations or Challenges of AWS Redshift
While AWS Redshift offers many advantages, it also has certain limitations and challenges that organizations should consider:
Query Performance for Small Datasets
Redshift is optimized for large-scale data analytics and may not provide optimal performance for small datasets or simple queries. For such scenarios, traditional relational databases might be more suitable.
Complex Setup and Configuration
Despite being a managed service, Redshift still requires some initial setup and configuration, including cluster sizing, node type selection, and data distribution strategies. These decisions can impact performance and cost, requiring careful planning.
Data Loading Complexity
Loading data into Redshift can be complex, especially for organizations with diverse data sources or real-time data requirements. Proper ETL processes need to be established to ensure efficient data loading and transformation.
Limited Transactional Capabilities
Redshift is designed primarily for analytical workloads and has limited support for transactional processing. It’s not suitable for online transaction processing (OLTP) applications that require frequent updates and inserts.
Storage Costs
While Redshift offers cost-effective compute resources, storage costs can accumulate for large datasets. Organizations need to implement proper data lifecycle management strategies to control storage costs.
Query Concurrency
Redshift has limitations on the number of concurrent queries it can handle efficiently. For applications requiring high concurrency, additional configuration or alternative solutions might be necessary.
Learning Curve
Despite offering a familiar SQL interface, Redshift has specific features and optimizations that require learning. Organizations may need to invest in training to fully leverage Redshift’s capabilities.
Data Type Limitations
Redshift has some limitations regarding supported data types and functions compared to traditional relational databases. These limitations might require adjustments to existing queries or data models.
How to Get Started with AWS Redshift
Getting started with AWS Redshift involves several steps, from creating an AWS account to launching and configuring a Redshift cluster:
Create an AWS Account
If you don’t already have one, sign up for an AWS account. This will allow you to access AWS services, including Redshift. During the sign-up process, you’ll need to provide contact and payment information.
Launch a Redshift Cluster
Once you have an AWS account, you can launch a Redshift cluster through the AWS Management Console:
- Sign in to the AWS Management Console and open the Amazon Redshift console.
- Click “Create cluster” to start the cluster creation workflow.
- Select the type and number of nodes for your cluster. For testing purposes, consider starting with a single-node cluster.
- Configure the database name, database port, master user name, and master user password.
- For cluster permissions, choose the default option to allow access from resources and accounts you own.
- Select your preferred VPC and subnet from the network and security options.
- Leave the database encryption option enabled for security.
- Click “Create cluster” to launch your Redshift cluster. It can take several minutes for the cluster to finish being created.
Configure Access
Set up inbound rules in your cluster’s Security Group to allow access from your local machine or applications. By default, a Redshift cluster blocks all incoming connections, so this step is essential for connecting to your cluster.
Connect a SQL Client
Install a SQL client like SQL Workbench/J to connect to your Redshift cluster. Use the endpoint and database credentials to log in and start querying your data.
Load Data into Redshift
Once your cluster is set up and accessible, you can start loading data. Redshift supports various methods for data loading, including:
- Using the COPY command to load data from Amazon S3
- Using AWS Data Pipeline or AWS Glue for ETL processes
- Using third-party ETL tools that support Redshift
Optimize Your Cluster
After loading data, optimize your cluster for performance by:
- Defining appropriate distribution keys and sort keys for your tables
- Implementing proper compression encodings
- Analyzing and vacuuming tables regularly
- Monitoring query performance and making adjustments as needed
Set Up Monitoring and Maintenance
Configure CloudWatch alarms to monitor your cluster’s performance and health. Set up automated snapshots for backup and recovery purposes, and implement a regular maintenance schedule to ensure optimal performance.
Scale as Needed
As your data and query requirements grow, scale your Redshift cluster by adding more nodes or upgrading to more powerful node types. Redshift makes this process relatively straightforward, with minimal disruption to ongoing operations.
Alternatives to AWS Redshift
While AWS Redshift is a powerful data warehousing solution, several alternatives exist that might be more suitable for specific use cases:
Snowflake
Snowflake is a cloud-based data warehousing platform that offers similar capabilities to Redshift but with a unique architecture that separates compute and storage. This separation allows for more flexible scaling and potentially better cost management for certain workloads.
Google BigQuery
Google BigQuery is Google Cloud’s serverless, highly scalable data warehouse. It offers automatic scaling and a pay-per-query pricing model, which can be advantageous for organizations with intermittent analytical needs.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics (formerly SQL Data Warehouse) is Microsoft’s data warehousing solution that integrates with the broader Azure ecosystem. It offers both serverless and dedicated resource models, providing flexibility for different workloads.
Amazon Athena
For organizations already using AWS, Amazon Athena offers a serverless query service that allows you to analyze data directly in Amazon S3 using standard SQL. While not a full data warehouse, it can be a cost-effective alternative for specific analytical needs.
Apache Hadoop and Spark
For organizations preferring open-source solutions, Apache Hadoop and Spark provide distributed processing frameworks that can handle large-scale data analytics. These solutions offer more flexibility but require more management overhead compared to managed services like Redshift.
Databricks
Databricks provides a unified analytics platform built on Apache Spark, offering data engineering, collaborative notebooks, and machine learning capabilities. It’s particularly well-suited for organizations with a strong focus on data science and machine learning.
Oracle Autonomous Data Warehouse
Oracle’s cloud-based data warehouse offers self-driving, self-securing, and self-repairing capabilities, reducing administrative overhead. It’s particularly appealing for organizations already invested in the Oracle ecosystem.
Amazon EMR
Amazon EMR (Elastic MapReduce) is a cloud-based big data platform that uses open-source tools such as Apache Spark, Hive, and Presto. While not a traditional data warehouse