
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687 |
+91 8409492687 |  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours on Instagram and YouTube and waste money on coffee and fast food, but won’t spend 30 minutes a day learning skills to boost our careers.
Master in DevOps, SRE, DevSecOps & MLOps!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Source:- whatmatrix.com
Year after year, we bear witness to the increasingly rapid evolution of the IT industry. It has now been more than two decades since the groundbreaking slogan ”Write once, run anywhere“ set a whole new level of expectation for the software development community. And here we are today, with a resulting, ever-expanding set of tools that have collectively taken Java development in particular, and software development in general, to a whole new universe of possibility.
Methodologies such as Agile, DevOps, and Continuous Integration and Deployment – along with the evolution of microservices – have collectively boosted software development process productivity to a point where it is a pleasure to be developing software more than ever before.
Utilizing automation and setting up the correct set of tools can make the development and delivery of software products surprisingly painless.
This article will take a look at this new universe from the perspective of a Java developer who crosses into DevOps and searches to optimize product development and delivery to its maximum.
Today, terms such as Spring Boot, Docker, Cloud, Amazon Web Services, Continuous Delivery are widely used but less widely understood. This article will take the easiest route possible to present all these technologies and explain these terms, and wrap it up in the form of a tutorial where we will develop a small piece of software and prepare it for production delivery using all the mentioned tools.

Why These Tools?
Simplify Deployments with Docker
”Write once, run anywhere“ was the conceptual breakthrough that yielded technologies like the Java Virtual Machine (JVM) which enabled your code to run anywhere. And now here we are, a couple of decades later, with something called Docker being presented to the IT community. Docker is a containment tool in which you can place your software and run it painlessly, almost anywhere you wish.
However, a Java developer may look at Docker and say “Why would we need that, we already have the JVM, which is well recognized as the master portable solution.” But is it?
”Write once, run anywhere“ sounds nice, and plays out well… at least most of the time. Until you encounter multiple JVM vendors, multiple Java versions, multiple operating systems, and various permutations and combinations of all the above. You then find yourself switching from the elegant ”Write once, run anywhere“ paradigm to the counter-productive ”Write once, debug everywhere“ pitfall.
And that’s where Docker comes in to help save the day.
Docker simplifies development, testing, and shipping of software. If you have the software you want to test, put it in the Docker container, and it will run and be painless to install for all the parties involved.
Speed Up Development with Spring Boot
Less than a decade after the “run anywhere” slogan was introduced, the Spring framework appeared on the scene. Today, the Spring ecosystem continues to flourish, and has produced lots of valuable Spring-based projects, perhaps most notably Spring Boot. As stated on the Spring Boot website:
Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”.
Spring Boot enables you to bring the application up and running in a matter of minutes. Software developers can focus on software development and then can benefit from a tool that does all the configuration for them.
In this tutorial, we will use Spring Boot to develop our microservice.
Continuous Integration (CI) with Jenkins
DevOps is a rapidly growing movement that is tightly integrating software development and systems administration teams, with the goal of making a software development and delivery lifecycle as painless, seamless, and productive as possible for all parties involved: developers, sysadmins, testers, and ultimately, end users.
Continuous integration (CI), is one of the cornerstones of the DevOps revolution. The idea is that whenever a developer commits code to the code repository, it is automatically tested and packaged for delivery (deployment) to production.
CI goes hand-in-hand with:
- Continuous Delivery – Automatic delivery of the package prepared for end user business testing with manual trigger to production deployment.
- Continuous Deployment – Automatic deployment of the packaged product directly to production.
More than a few tools exist which can be utilized for implementing the CI process. One of the most popular is Jenkins, an open source CI tool. With more than a thousand plugins and a huge community behind it, Jenkins is an easy choice when starting to think about implementing continuous integration, delivery, or deployment.
In our tutorial, Jenkins will be used to deliver our product to the cloud, more specifically, the Amazon (AWS) cloud.
Cloud Computing with AWS
If you have some sysadmin experience, imagine removing some of the worries of system administration from your shoulders. You have a few applications; you have an idea of how much resource they will require, but you don’t know exactly the hardware sizing you will need. You make the estimation, the resources are bought, and the system goes to production. If you are lucky, you will find that you overestimated and have more resources than you need. But given Murphy’s Law, you will more likely find that you underestimated resource requirements and end up scrambling to get a bit more memory or processing power under tremendous time pressure. In contrast, if you’re deploying to the cloud, you simply put your system out there and size it as needed, with the flexibility offered by the cloud providers. With the cloud, you neither need to worry about running out of system resources, nor do you need to worry about having 90 percent of your memory or CPU sitting idle.
Of course, there is the challenge of deciding which provider to choose. Cloud wars are still in progress. Clash of Microsoft, Amazon and Google for the future of computing is an example title you can find lately in tech-world news. For this blog, I have chosen Amazon Web Services (AWS), largely based on its current popularity and market share.
One of the advantages of AWS is that Amazon offers lots of services after you sign up
In this tutorial we will use the following two AWS services: Elastic Compute Cloud EC2 (more specifically, Amazon EC2 Container Registry, or Amazon ECR), and Amazon S3 (Simple Storage Services).
Amazon ECR
We will need to store our Docker images somewhere. Amazon ECR is a managed AWS Docker registry service. As stated on the Amazon ECR web site:
…makes it easy for developers to store, manage, and deploy Docker container images. Amazon ECR is integrated with Amazon EC2 Container Service (ECS), simplifying your development to production workflow. Amazon ECR eliminates the need to operate your own container repositories or worry about scaling the underlying infrastructure.
Amazon S3
As mentioned, the application we develop will be a Spring Boot microservice that will be uploading files to Amazon S3. As stated on the Amazon S3 web site:
…provides developers and IT teams with secure, durable, highly-scalable cloud storage. Amazon S3 is easy to use object storage, with a simple web service interface to store and retrieve any amount of data from anywhere on the web.
A Practical “How To” Tutorial
The goal is to prepare for deployment a Spring Boot microservice which will upload files to Amazon S3. Steps are the following:
- Develop the microservice
- Define the build process in which the service will be dockerized
- Use Bitbucket for hosting the Git code repository
- Integrate Bitbucket with Jenkins to package the application using Gradle
- Push it to a remote Amazon ECR
What follows is a tutorial for setting up all the needed components:
- Spring Boot example application – microservice packaged and dockerized using Gradle
- Jenkins installation on a fresh Ubuntu server
- Bitbucket integration with Jenkins via webhook
- Jenkins job configuration
- Amazon ECR to store the Docker images containing our application
Prerequisites
To be able to use AWS cloud resources, we need to register at Amazon first. By registering, we will get an account with immediate Free Tier usage benefits, for purposes of enabling hands-on experience during the 12 months following registration.
As mentioned, in this tutorial we will use Amazon S3 and Amazon ECR. For both, we will need access keys to connect to the services.
After signing up with AWS, we go to our account Security credentials, where we choose Access keys and click on “Create New Access Key”. After clicking, a key is generated along with its ID. You need to store this somewhere safe, as we will use it later when configuring AWS Jenkins integration and developing our S3 file upload.
The next prerequisite is that we need an Amazon S3 bucket (storage container). Our Spring Boot Service will be uploading and downloading files to and from Amazon S3 storage. Bucket creation is simple enough and just requires few clicks. A full description of how to do it is provided in the Create a Bucket documentation.
We will also be using Bitbucket for hosting our code and triggering requests to Jenkins, so a Bitbucket account is needed as well. Bitbucket is a great option for developers, with one of its main benefits being the unlimited amount of private repositories you can create.
Application Development
Rather than getting into all the details of Spring annotations and how they work, I will instead focus, from a pure developer perspective, on the more challenging part of the whole setup; namely, installing and configuring Linux, Jenkins, and other tools needed for CI. All the code examples used in this tutorial, including the Spring Boot microservice application, are available on the Bickbucket repository for the project.
Our application composition is simple. We have a Spring Boot application entry point in our StorageWebserviceApplication.java file. The logic for uploading and downloading files is in StorageService.java. StorageController.java is a Rest controller, containing API endpoints used for file upload and download. Here is the project hierarchy:
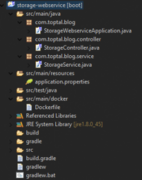
We have chosen Gradle as a build tool, and it will package our application and compose the Docker image. So next, we will discuss the Gradle build file, service component, and the Dockerfile.
To be able to use AWS API, we need to include dependencies in our build file, as defined in the AWS documentation for using Gradle.
Summed up, the AWS dependency configuration part of our Gradle script will look like the following:
buildscript {
...
repositories {
mavenCentral()
}
dependencies {
...
classpath("io.spring.gradle:dependency-management-plugin:0.5.4.RELEASE")
}
}
..
apply plugin: "io.spring.dependency-management"
dependencyManagement {
imports {
mavenBom ('com.amazonaws:aws-java-sdk-bom:1.10.47')
}
}
dependencies {
..
compile ('com.amazonaws:aws-java-sdk-s3')
}
As stated previously, when uploading files to Amazon S3, we do so by uploading files to an S3 bucket.
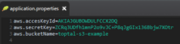
To connect to the bucket, our Amazon S3 client needs to have credentials provided. Credentials are the access keys we created earlier. We define the access key ID and value in the application.properties file; we have named our bucket toptal-s3-example.
Our main service component is now as follows:
@Service
public class StorageService {
@Value("${aws.accesKeyId}")
private String awsAccessKeyId;
@Value("${aws.secretKey}")
private String awsSecretKey;
@Value("${aws.bucketName}")
private String awsBucketName;
private AWSCredentials credentials;
private AmazonS3 s3client;;
@PostConstruct
public void init(){
credentials = new BasicAWSCredentials(awsAccessKeyId, awsSecretKey);
s3client = new AmazonS3Client(credentials);
}
public void uploadFile(MultipartFile file) throws IOException {
File fileForUpload = transformMultipartToFile(file);
s3client.putObject(new PutObjectRequest(awsBucketName, file.getOriginalFilename(), fileForUpload));
}
public InputStream downloadFile(String amazonFileKey) throws IOException {
S3Object fetchFile = s3client.getObject(new GetObjectRequest(awsBucketName, amazonFileKey));
InputStream objectData = fetchFile.getObjectContent();
return objectData;
}
…
StorageService reads the credentials from the application.properties file and uses them to instantiate BasicAWSCredentials object, and subsequently the AmazonS3Client object. What follows is a simple matter of invoking putObject for file upload and getObject for file download, on the Amazon S3 client object.
We will run the service inside a Docker container and, during the Gradle build process, we will build the Docker image. We will do this by additionally configuring the build.gradle file, as follows:
buildscript {
...
dependencies {
...
classpath('se.transmode.gradle:gradle-docker:1.2')
}
}
.....
apply plugin: 'docker'
...
task buildDocker(type: Docker, dependsOn: build) {
push = false
applicationName = "storageservice"
dockerfile = file('src/main/docker/Dockerfile')
doFirst {
copy {
from jar
into stageDir
}
}
}
The Buildscript part and apply plugin are pretty standard. We have also defined a buildDocker task which reads the Docker configuration stored in the src/main/docker/Dockerfile, and copies the JAR file to the Docker build.
Dockerfile contains a list of pure Docker commands with which we will prepare our image:
FROM frolvlad/alpine-oraclejdk8
ADD storageWebService-0.0.1-SNAPSHOT.jar storageService.jar
EXPOSE 8080
CMD ["java", "-Djava.security.egd=file:/dev/./urandom", "-jar", "/storageService.jar"]
A prerequisite for running our application is to have installed a Java Virtual Machine (JVM). Docker provides a list of images with Java installed, and we will choose one of the smallest, based on a minimal 5MB Alpine Linux. frolvlad/alpine-oraclejdk8 image has all that we need and is quite small (just 170 MB).
The FROM command sets the mentioned image as the base on which our own will be built. We ADD the built JAR file to the container filesystem under the name storageService.jar. Next, we define for Docker container to listen on port 8080 at runtime with the EXPOSE command. This, however, will not enable communication to 8080 from the host. When the image is done, and we want to run it, we will also need to publish the port on the container with the following command docker run -p 8080:8080 amazonRepository/storageservice, where amazonRepository is a repository we will configure later in this tutorial. With CMD, we define which commands will be executed when we run the container. Values in the brackets of the CMD command simply mean the following will be executed when we run the container:
java -Djava.security.egd=file:/dev/./urandom -jar /storageService.jar
The option -Djava.security.egd=file:/dev/./urandom is needed to help mitigate JVM delays during startup. If omitted, it will make the application boot up extremely slow due to a random number generation process needed during the boot process.
This sums up the “Application development” part. With this done, the service we have created here will be automatically started when we run a Docker container later on. So, let’s start installation and configuration of the other tools needed to set up the continuous integration process.
Application and System Operations
First off, we need a clean Linux server on which to set up the Jenkins CI tool. Note that the following instructions are specifically for Ubuntu 14.04. Keep in mind instructions may slightly differ for other Linux distributions. The Jenkins version used is 2.7.1 and screens and instructions may differ slightly depending on the version of Jenkins being used.
So, we go to our Linux server console and start installing the prerequisites.
JDK Prerequisite
We need to have a JDK installed. Following are instructions for installing JDK8.
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get install python-software-properties
sudo apt-get update
sudo apt-get install oracle-java8-installer
java -version
Install Docker
For Jenkins to be able to trigger Docker builds, we need to install docker-engine as follows:
sudo apt-get install apt-transport-https ca-certificates
sudo apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
#create a docker list file
sudo vi /etc/apt/sources.list.d/docker.list
#add the following entry in the docker.list file (change trusty to #the release you are running on if you are running on different, ie. #xenial, precise...):
deb https://apt.dockerproject.org/repo ubuntu-trusty main
#save and exit the file
sudo apt-get update
apt-cache policy docker-engine
sudo apt-get install docker-engine
As we have now installed the Docker engine, with the following command we will start a hello-world Docker image to confirm Docker works correctly.
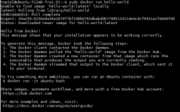
sudo docker run hello-world
Hello-world image output will look as follows, and with this, we can confirm that the engine is working ok.
Install AWS Command Line Interface (CLI)
Next, we will install the AWS CLI. Later on, in Jenkins job configuration, we will use the CLI to execute commands for AWS authentication and Docker image push to Amazon EC2 container registry.
To install the AWS CLI, we follow the guidelines described in details on the Amazon CLI documentation.
Of the two installation options, we will choose installation using Pip, a package management system used for installing and managing Python programs. We will install Pip and AWS CLI simply by running the following three commands:
#install Python version 2.7 if it was not already installed during the JDK #prerequisite installation
sudo apt-get install python2.7
#install Pip package management for python
sudo apt-get install python-pip
#install AWS CLI
sudo pip install awscli
AWS ECR
As the last step of the build process, we will be pushing our Docker image to the Amazon container registry. In the Amazon web services console, we find the AWS EC2 Container Service.
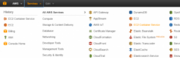
We select Repositories submenu on the left and click on Get started.
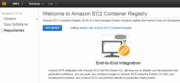
We are then presented with the first screen for configuring the repository where we enter the repository name and click on the Next Step button.

Clicking on Next Step then shows us a screen with instructions on how to push images to the repository.

We are presented with an example of how to build and push a Docker image to the registry, but we don’t need to concern ourselves with this now. With this, we have created a repository.
Install and Configure Jenkins
To install Jenkins, we enter the following commands in the shell:
#Download Jenkins key and pipe it to apt-key tool, apt-key command #add will read from input stream, as defined by „–„. When added
#apt will be able to authenticate package to be installed.
wget -q -O - https://jenkins-ci.org/debian/jenkins-ci.org.key | sudo apt-key add -
#create a sources list for jenkins
sudo sh -c 'echo deb http://pkg.jenkins-ci.org/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
#update your local package list
sudo apt-get update
#install jenkins
sudo apt-get install jenkins
When the installation finishes, Jenkins starts automatically. Check the service status with the following command:
sudo service jenkins status
Jenkins will be connecting to Bitbucket Git repository, and to do so, we need to install Git.
#install Git
sudo apt-get install git
Jenkins will be triggering Gradle build process, during which a Docker image will be created. To be able to do this, the Jenkins user needs to be added to the docker user group:
#add Jenkins user to docker user group
sudo usermod -aG docker jenkins
During the build process, Jenkins will be pushing Docker images to Amazon ECR. To enable this, we need to configure AWS for the Jenkins user.
First, we need to switch to the jenkins user. To do so, we need to set a password.
#change Jenkins password
sudo passwd jenkins
#switch to Jenkins user
su – jenkins
#configure AWS
aws configure
After entering the aws configure command, we start inputting the generated secret access key and key ID (these are the credentials we generated earlier in the process). In my case, the account’s region is us-west-2, and so I input that. We also set the default output format for AWS commands to be JSON.

We can now move on to configuring Jenkins through the web console accessible on port 8080.
When we access the URL, we are presented with the following Getting started screen.
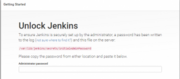
As stated on the screen, we need to input the password. Having done this, the setup wizard prompts us to do the following:
- Choose which plugins to install – we will choose Install suggested plugins.
- Create first admin user by inputting user credentials
When done, click Save and Finish. With this, we have finished Jenkins setup configuration.
Before we start defining the build job, we need to add a few additional plugins. We will go to Manage Jenkins and click on Manage plugins. In the Available tab, we first find the Bitbucket plugin, check the box, and click on Download and install after restart.
You will then be presented with something like the following screen.
After plugin installs, we repeat the process for the following additional plugins that will be needed to set up the job:
- Gradle plugin
- Docker build step plugin
- Cloudbees Docker custom build environment plugin
- Amazon ECR plugin
The Docker build step plugin we use will send requests to the Docker daemon. For this purpose, we need to enable the TCP socket on port 2375. To do to so, we enter the Docker configuration file located at etc/default/docker.
sudo vi /etc/default/docker
Here we add the following line in the configuration:
DOCKER_OPTS='-H tcp://127.0.0.1:2375 -H unix:///var/run/docker.sock'
We save and exit the file and restart both Docker and Jenkins service.
sudo service docker restart
sudo service jenkins restart
After Jenkins reboots, we go to the Jenkins console and, from Manage Jenkins, we choose Configure System.
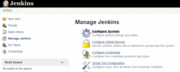
We find the Docker builder section and enter http://localhost:2375 for the REST API URL, click on Apply to confirm the change. We then click the Test Connection to hopefully confirm that everything is ok.
We save the configuration and proceed to Jenkins job configuration.
Job Configuration
We go to the Jenkins home page and create a New Item.
We choose a Freestyle project and enter the project name as shown on the following screen:
Clicking on OK, we are presented with the job configuration page. We want the project to be built on each push to our Bitbucket Git repository. To achieve this, we first need to define the repository we are connecting to.
Step 1: Source Code Management
Under source code management, we choose Git and enter the URL of our Bitbucket repository. The URL has the form of https://bitbucket.org/bitbucketUsername/repositoryName.
After we enter the URL, Jenkins will automatically try to test the connection. Since we didn’t yet input credentials, it will show an error indicating it cannot connect.

Open the drop down list Add, and click on Credentials Jenkins provider.
We are presented with the following screen, where we enter the username and password for our Bitbucket account
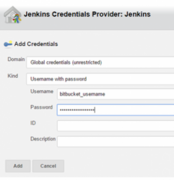
After adding the new credentials record, we make sure to select it in the credentials drop down, and this finishes the Source code management setup.
Step 2: Build Triggers
Check Trigger builds remotely and define an authentication token. Make sure to define a random and secure token.
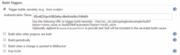
Step 3: Bitbucket Webhook
Jenkins already provided the URL for us which we will use on Bitbucket. We go to our Bitbucket repository page and, in the settings menu, click on Web hooks. Subsequently clicking on Add webhook presents us with the following screen, which we fill in as follows:
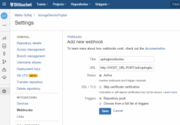
URL has the following structure: http://JENKINS_URL _HOST:PORT/job/JOB_NAME/build?token=TOKEN.
Enter the values above respectively with the Jenkins URL, port it is running on, the name of the job you have created, and token you have previously defined.
After saving the Webhook, you will be provided with the following screen, which you can edit if needed, or view requests generated each time we push new code.
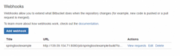
With this configuration, the webhook is triggered on each repository push, regardless of the branch. On the Jenkins side, we can define which branch push will trigger the build.
For Bitbucket to be able to push code to Jenkins, we need to reconfigure Jenkins global security to allow anonymous read access. Additionally, for our setup, we have to disable the default Jenkins option which prevents cross-site request forgery. To do this, go to Manage Jenkins and choose Configure global security. Check Allow anonymous read access and check Prevent cross-site forgery exploits. Then save the configuration.

Please note that this is only done for simplicity reasons. Full setup surpasses the coverage of this tutorial, and it would include further securing Jenkins behind a reverse proxy, on TLS connection, and enabling CSRF prevention.
Step 4: Gradle Build
We can now return to the Jenkins job and continue configuring it. In the build section, we add a build step: Invoke gradle script.
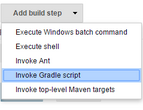
On this form, we enter the following:
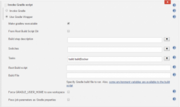
As shown on the screen, we will use the Gradle wrapper, a convenient Gradle feature that doesn’t require you to have Gradle installed on the host. Make sure to check the Make gradlew executable box.
In the tasks, we specify build and buildDocker.
Step 5: Docker Tag Image
This part of the build tags a Docker image previously prepared by Gradle’s dockerBuild task. For this, we add a new build step to the job: Execute Docker command. We choose the Tag image command and set the image name, target repository where we will push the image, and tag:
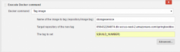
Step 6: Docker Push to Amazon ECR
Lastly, we need to define how to push our image to the Amazon ECR. For this, we add a new Execute shell build step and set the commands to authenticate to AWS and to push the image to Amazon ECR:
#region for our account is us-west-2
aws ecr get-login --region us-west-2 | bash
#push the previously tagged image
docker push 058432294874.dkr.ecr.us-west-2.amazonaws.com/springbootdocker:${BUILD_NUMBER}

With this, we have finished our build process. After pushing new code to the repo, this job will activate, and we will have a new Docker image uploaded to the Docker registry “auto-magically”.
The image can be then pulled to wherever we have docker-engine installed, and can be run with the following command:
docker run -p 8080:8080 amazonRepository/springbootdocker
This command will start our Spring Boot microservice, with the following endpoints for uploading and downloading our files to the S3 bucket:
http://hostnameURL:8080/api/storage/uploadhttp://hostnameURL:8080/api/storage/download?fileName=xyz
Further Steps with Java and Continuous Integration
There are always more things to do. A lot of ground has been covered in this tutorial, but I would consider this only a starting point from which to learn further. Putting Jenkins behind a web proxy server, like Nginx, and establishing a TLS connection, are only two examples of what more could, and arguably should, be done.
Our Docker image is available on Amazon ECR and ready for deploying. We can now take it and deploy it manually. However, a finer solution would be to automate it further. CI is only the first step, and next step is Continuous Delivery. What about a high availability? Amazon AWS EC2 provides features for registering containers in the cloud on a clustered environment which is mandatory for production based service. A good working example of developing a continuous delivery process can be found on the following AWS blog post.
Conclusion
All in all, we have put in place a smooth and clean software development process. Utilizing the tools available, we have created an infrastructure that helps maximize our productivity. Now, we do not have to worry about the configuration of our Java service which is a simple web service with a REST endpoint. We let the Spring Boot convention take care of everything and focus only on the service logic. We utilize Jenkins to build a new Docker image each time we push our code to our Bitbucket Git repository, and in the end, we’ve set the cloud to be responsible for storing our Docker images and files. When we deploy our service contained within a Docker image, we will be care free of any restrictions of the operating system (as long as the operating system has a docker-engine installed).